どこにこの内容を上げていこうかなと悩んで、結局良いところが思いつかなかったので、GitHub Pagesに連載として上げていこうと思う。
今日は第一回 (#1) ということで、連載で何を伝えていくかの概要を書くことにする。
- Logseqがなぜ思考整理やタスク管理に向いているのか
- ObsidianやHeptabase、Notionなどとの違い
- クエリやClojureについて
- DB版について
とりあえず今回はアブストという感じなので、気楽にななめ読み程度に見てもらえればと思う。
Logseqがなぜ思考整理やタスク管理に向いているのか
Logseqをここ数年メモやタスク管理に利用しているのだけれど、他のツール、Notion等と比べて最も長く継続して利用できている。もちろんこのブログ自体がそうであるようにObsidianも併用しているのだけれど、Logseqがなぜ使いやすいのか、Obsidianではなぜダメなのか、なぜ自分に合っているのかにはきちんとした理由がある。
最大のポイントは、Logseqは行(ブロック)を単位とするデータベースである ことに尽きる。ここがObsidianやNotion等との最大の違いであり、追々語っていきたいClojureを使ったクエリ、他のデータベースでいうところのSQL等をうまく活用できる点であり、書いたことが一切埋没せずにすべてが財産になる 点でもある。
ObsidianやHeptabase、Notionなどとの違い
Obsidian等のページ単位のノートを使っていて、読み返すことはあるだろうか。自分は時々100ページくらいあるうちの2,3ページは目を通すけれど、それ以外はほぼ目を通すことはない。ましてやタグで整理しているだけで、それ以上の整理はなにもしない。
一方で、Logseqであれば、まず何もしなくても自動的にキーワードで双方向リンクが貼られる。この点はObsidianも同様なのだけれど、行(ブロック)が単位であるため、#ハッシュ 記法を使っていくことでより綺麗に自然に思考が整理され、不思議とWikiのようなページが財産として溜まっていく。後々の検索性も高く、TODO / DONE などの記法と併用することでタスク管理もしやすい。
Notionでもデータベースはある。しかし、データベースとして最初から作ったものでないとデータベースのデータにはならない。そして、クエリもデータベース単位に限られる。
ObsidianもDataviewを使えば可能だが、Dataviewを意識して使っていくことになり、Obsidian本来の用途とは少し異なるうえに、プラグインのインストールが必須となる。
Heptabaseは比較的考え方がLogseqに似ているものの、行(ブロック)単位の管理が徹底されていないため、ノートが散乱しがちで、クエリを書くこともできない。クエリを書くことができないということは、当初思った方向でしか思考は整理されず、結局ホワイトボード機能ばかりを使うことになるし、検索しきれないノートは埋没して忘れ去られていく。
クエリやClojureについて
前述のとおり、Clojureを使ったクエリがLogseqの真骨頂なのだけれど、それについてはここに書ききれないので、追々少しずつ語っていきたいと思う。
例えば自分は、#経費精算 というページに以下のようなClojureによるクエリを書いている。これは TODO になっている経費精算を自動で一覧化するもので、SQLみたいなものと思ってもらって良い。
#+BEGIN_QUERY
{:title "経費精算 (TODO、直近50)"
:query (and (or [[経費精算]] [[経費]] [[領収書]] [[経費関係]]) (and (not (todo DONE)) (not (TODO DOING))) (not "alias::") (not (page [[ダッシュボード]])) (not (page [[経費精算]])) )
:result-transform (fn [result]
(let [rev-pri (fn [p] (case p "A" "Z" "B" "Y" "C" "X" "Z" "B" "A"))]
(->> result
(sort-by (fn [r]
[
(rev-pri (get r :block/priority "Z"))
(get (get r :block/page) :block/journal-day "19000101")
]
))
reverse
(take 50)
(map (fn [m] (update m :block/properties
(fn [u]
(assoc u
:journal-day (get (get m :block/page) :block/journal-day)
)
))))
)))
:breadcrumb-show? false
}
#+END_QUERYこれによって実際のデータをクエリすると、以下のような表示ができる。
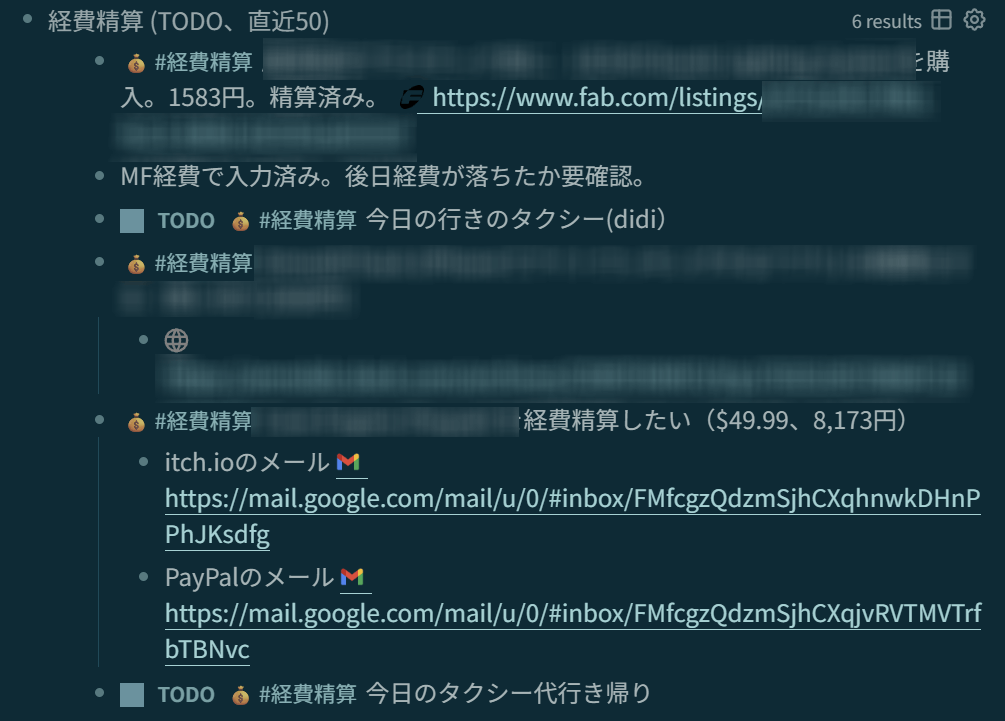
これらはもちろんこの箇所に打ち直したりコピーしたりする必要はなく、データベースでいうところのビューとして、ページのコンテンツの一部として表示される。そして、そのコンテンツが内包されているページ自体も、他のページから参照することができる。(ただしビュー内のコンテンツが二重に検索結果に出ることはない。)
DB版について
Logseqには、アプリ版、つまりMarkdownベースのファイルバージョンではなくて、DB版 (※ 詳しくは この記事など ) というウェブサービスバージョンも存在し、複数人で使ったりできるらしいが、私はあまり詳しくないのもあり、今回の連載では割愛する。
まとめ
上記のような内容を、次回以降掘り下げていこうと思う。Logseqでどう思考整理やタスク管理がスムーズにいくのか、どういう人に向いているのかなどを、少しずつ紐解いていけると良いなと思う。
次回は特に、Logseqが「日誌 (Journal)」を基調にしている点、そしてそれ以外のページを作成する必要がほとんどない点について解説していければと思う。